Why LLMs Waste Tokens (And What You Can Do About It)
Your LLM has no memory between requests, so every API call re-transmits everything. Why the waste compounds and the three practical fixes.
Your LLM is not using most of what you send it. You're paying for context it already has.
This is not a complaint about LLM quality. It is a description of how the architecture works, and why it creates a billing problem that most developers do not notice until the invoice arrives.
TL;DR
- Transformer models have no persistent memory between requests. Every API call must include the full context, retransmitted from scratch.
- For Claude Code, a 30-turn session resends roughly 1.5 million input tokens because earlier turns are repeated on every subsequent request.
- The biggest sources of waste are tool results (especially shell output), duplicate file reads, and stale conversation history that no longer informs the current task.
- Smarter models do not fix this. The waste is in transmission, not understanding. The API charges for what is sent, not what is used.
- Practical mitigations: tighter session scoping,
.claudeignorefor noise, and automated context distillation at the proxy layer (30-60% real-world reduction depending on session patterns; 20% conservative benchmark floor).
LLMs Have No Persistent Memory
Every Claude API request is processed in isolation. The model has no carry-over state from the previous request, no cached file content from earlier turns, no internal record of tool results it has already seen. To maintain coherence across a conversation, the entire history must be present in every single request, which is the source of the compounding cost.
This is a fundamental constraint of transformer-based language models, not a bug or a limitation of the particular product. The model processes a sequence of tokens and produces an output. Everything relevant to the conversation must be present in that sequence, every time. So your Claude Code session works like this:
- Turn 1: You send your message. Claude responds.
- Turn 2: You send your next message plus everything from turn 1: your message, Claude's response, tool results, file reads.
- Turn 3: You send your message plus everything from turns 1 and 2.
- Turn 30: You send your message plus the entire accumulated history of the previous 29 turns.
The context window is not a conversation interface. It is a document that grows with every turn, and you pay to transmit the entire document on every request.
What Accumulates
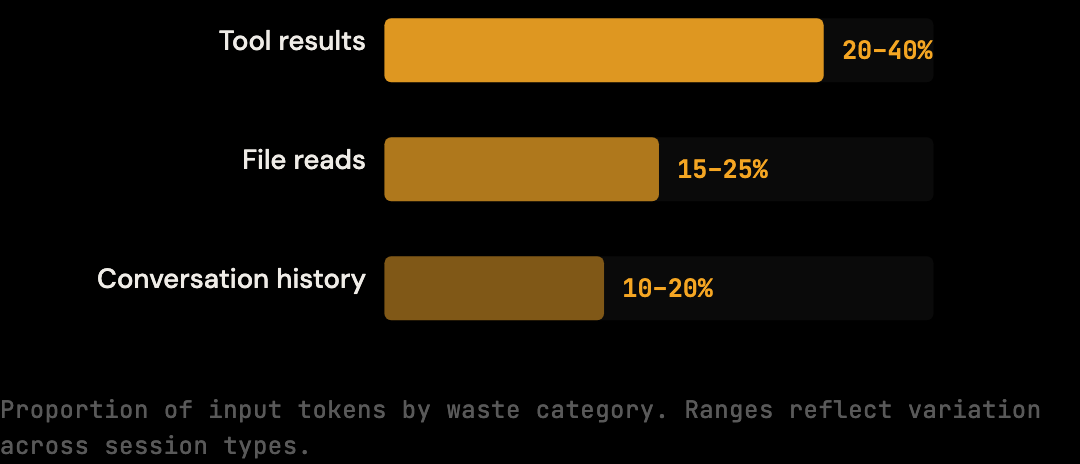
Three categories of content drive most of the input volume in a typical Claude Code session: tool results (especially shell output, often 20-40% of total context), file reads (a single 300-line file at 3,000 tokens can appear 3-4 times), and prior conversation history (Claude's earlier responses at 1,000-3,000 tokens each). All three carry forward on every subsequent turn.
Tool results are the biggest driver. When Claude Code runs a command (a build, a test suite, a file search), the full output gets added to the context. A test run that produces 200 lines of output adds 200 lines to every subsequent request, even if Claude only needed the final summary line.
File reads compound this. When Claude reads a 400-line source file to understand a function, those 400 lines enter the context. If you ask a related question two turns later, the same file might be read again. The same content appears twice. You pay for it twice.
Redundant conversation history layers on top. Early turns in a long session contain framing, clarification, exploratory exchanges, context that was useful at the time but carries diminishing relevance as the session evolves. It stays in the window regardless.
By the middle of a typical Claude Code session, a substantial fraction of the tokens being sent on each request are content the model has already processed, content that is largely redundant with other content in the window, or content that contains more information than the current task requires. You are paying for all of it.
The Math
Sonnet pricing is $3 per million input tokens. A typical 30-turn Claude Code session accumulates roughly 1.5 million input tokens because each turn resends the prior history. That works out to $4.50 per session before output tokens, or $180/month for a developer running two sessions per day across 20 working days. The per-token rate is low; the volume is what drives the bill.
Per-turn breakdown:
Turn 1: ~1,000 input tokens (your message, initial context)
Turn 10: ~20,000 input tokens (accumulated history)
Turn 20: ~40,000 input tokens
Turn 30: ~50,000 input tokens
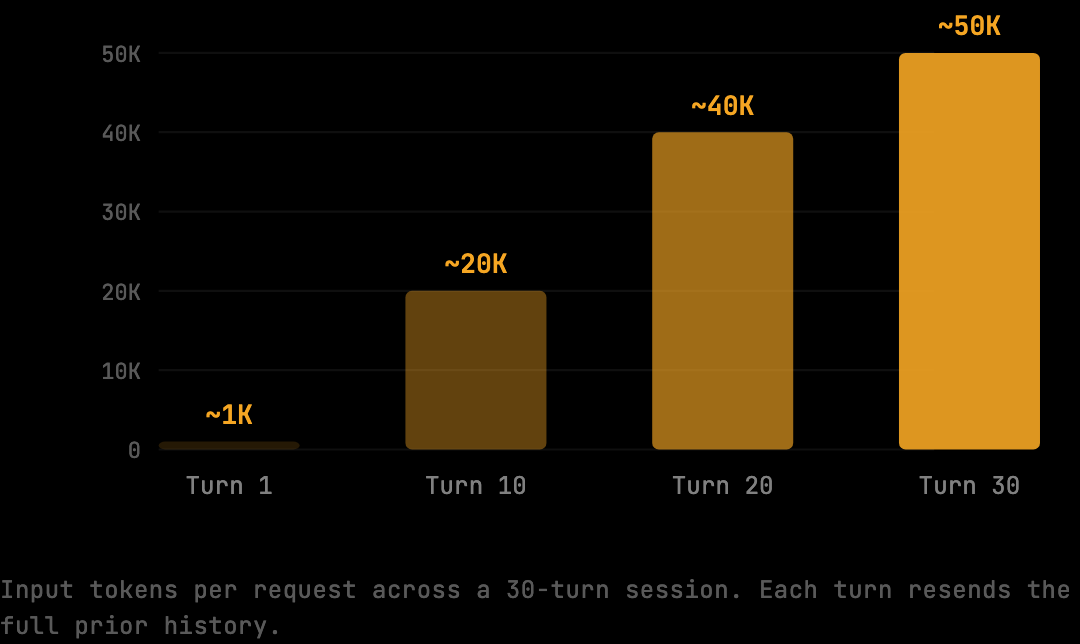
The total input tokens for that session is not 30 × 1,000. It is the sum of all those growing contexts, approximately 1.5 million tokens. At $3/M:
1,500,000 tokens × $3.00/M = $4.50 per session
Why Models Cannot Fix This
A common intuition is that smarter or larger models would solve token waste, that they should "remember" what they have already processed. This conflates intelligence (what the model does with input) with transmission (what gets sent on each request). The API charges for transmission. Even a perfect model has to receive the context to operate on it, and bigger context windows do not reduce cost — they just allow more to fit in.
Caching helps at the edges. Anthropic offers prompt caching that reduces costs on repeated static prefixes. But mid-session context, the part that grows with every turn, does not fit a simple caching model. It changes with each request.
What You Can Do About It
The practical levers are session scoping (deciding what enters), exclusion rules (blocking known noise), and automated distillation (removing redundancy at the proxy layer before requests reach the API). The first two require active developer attention; the third runs without intervention.
Scope your sessions. A session focused on a single file or function accumulates less irrelevant context than a session that ranges across the codebase. When a task is done, start a new context window.
Use .claudeignore. Large generated files, lock files, and build artifacts should not be readable to Claude Code at all. A .claudeignore file in your project root prevents them from entering context.
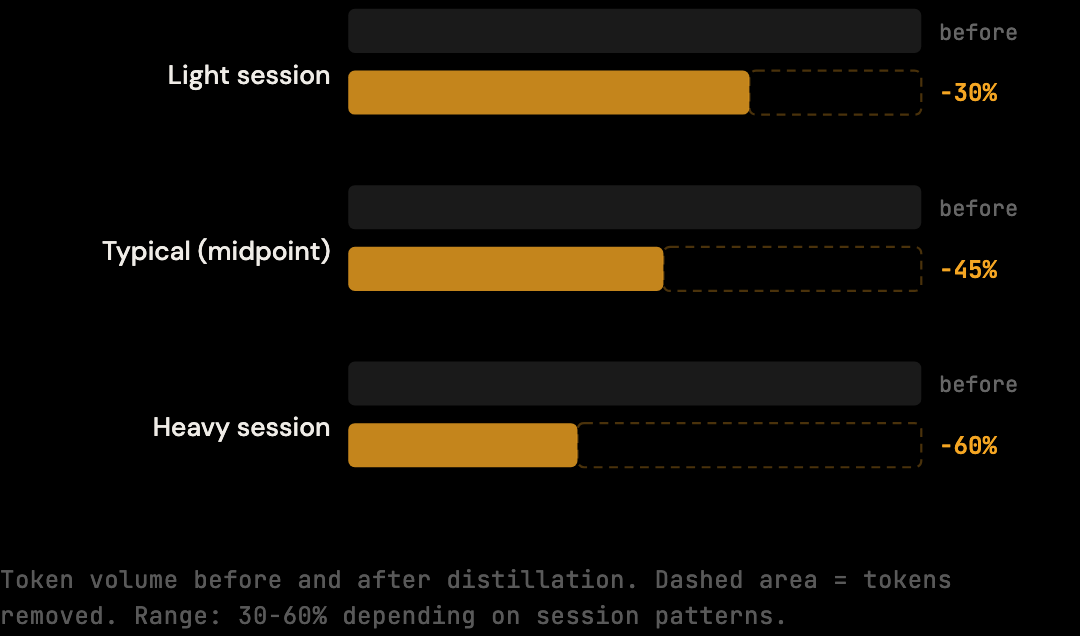
Distil context automatically. This is the approach with the broadest impact and the least behavior change. A token optimization proxy like The Distillery sits between Claude Code and Anthropic. Before each request leaves your machine, it analyzes the context and strips redundant content: duplicate file reads, verbose tool outputs, stale conversation history. You get the same Claude responses. You pay for less context. Real-world reduction is 30-60% depending on session patterns; the conservative deterministic benchmark floor is 20% on standard sessions (reproducible via npx tsx scripts/benchmark.ts).
How Anthropic Caching Differs From Distillation
Anthropic's prompt caching and proxy-layer distillation address different parts of the cost problem. Caching reduces the cost of static prefixes (system prompts, fixed instructions) by storing them on Anthropic's side and charging a reduced rate for cache hits. It is cheap when applicable but cannot help with content that varies across requests.
Distillation removes redundant content from the variable portion of the request, which is most of a Claude Code session. A duplicate file read at turn 8 is not a static prefix; it is a tool result that varies session by session. Caching cannot deduplicate it because the cache key depends on exact content match. Distillation detects the duplicate programmatically and elides it before the request reaches Anthropic.
The two are stackable. A request optimized by both pays the cached rate on its static prefix and reduced volume on its variable body. For workloads with both characteristics (Claude Code sessions with project-specific system prompts and varied tool results), the combined effect is larger than either alone.
What Token Waste Looks Like in Practice
A concrete example: a developer asks Claude to update an authentication function. Claude reads package.json (3,000 tokens) to check dependencies, then src/auth/session.ts (4,000 tokens) to understand the current implementation, then runs the test suite (2,500 tokens of output). That is 9,500 tokens of context on turn 3.
By turn 12, the developer has asked three follow-up questions. Claude has re-read package.json twice more (to check different fields), re-read session.ts once more (after a proposed edit), and re-run the test suite three more times. The same files appear repeatedly in the context, and each appearance is transmitted in full on every subsequent turn.
By turn 12, the input payload for that request is roughly 35,000 tokens. Of those, an estimated 14,000 tokens are content the model has already processed at least once: duplicate file reads, repeated test output, and prior assistant responses that are no longer informing the current sub-task. That 14,000 tokens of waste is then resent on turns 13 through whatever the session's final turn is. The cost is not just the waste itself but the waste multiplied by the number of remaining turns.
The Structural Reality
Token waste is not something you can fully eliminate by being more careful. It is structural. The accumulation mechanic is the mechanism that lets the model maintain context across a long session. You cannot turn it off without losing session coherence.
What you can do is reduce how much redundant content enters the growing context in the first place. That is what context engineering, whether manual or automated, is actually about.
Frequently Asked Questions
Q: Why does Claude not just remember what it has already read?
The model has no internal state between API requests. Each request is processed independently. To remember, the model would need to be sent the relevant prior content on each turn, which is exactly what the conversation history mechanism does. There is no efficient alternative to this within the transformer architecture.
Q: Does sending fewer messages reduce token waste?
Indirectly, yes. Fewer turns mean less accumulation, so the context grows more slowly and the per-turn payload stays smaller. The savings are real but bounded: a 10-turn session is genuinely cheaper than a 30-turn session, but the 10-turn version still resends the full 10-turn history on its last request.
Q: Will larger context windows make this problem worse?
Larger windows do not change the per-token cost; they just allow longer sessions before hitting hard limits. A 200K-token context window costs more than a 100K window when filled, because the bill scales with what is sent. Bigger windows are useful for capability (handling larger codebases) but neutral or negative for cost.
Q: Is there a way to cache mid-session context to avoid retransmission?
Anthropic's prompt caching handles static prefixes well. Mid-session content (varying tool results, growing assistant responses) does not match the cache because the content changes between requests. Proxy-layer distillation handles the variable portion that caching cannot reach. Both can be used together.
Q: How much waste is typical on a Claude Code session?
Real-world reduction is 30-60% depending on session patterns; the deterministic benchmark floor is roughly 20% on standard fixtures. The variation depends on session patterns: sessions with heavy shell output, repeated file reads, or long conversation history have more removable redundancy than tightly scoped sessions with conversational turns.
If you want to see the exact reduction numbers on a realistic session corpus, the benchmark page walks through the methodology and results.
If you are ready to start reducing your bill now, install The Distillery in two minutes.
Try it on your own Claude Code sessions.
The Distillery applies these distillations automatically. Free until it saves you something.