Claude Code Token Usage: Why Each Session Costs More Than the Last
Turn 1 sends 1,000 tokens. Turn 20 sends 50,000+. Why every Claude Code session costs more than the last, and the math behind the curve.
Your Claude Code sessions are not expensive because you ask complex questions. They are expensive because of what gets sent on turn 20 that was never needed on turn 1.
This is the compounding mechanic at the center of Claude Code's cost structure. Understanding it precisely changes how you read your bill, and which approaches to cost reduction actually work.
TL;DR
- Every Claude Code request resends the full conversation history, not just the latest message. Earlier turns are paid for again on every later turn.
- Turn 1 sends ~1,000 input tokens. Turn 20 sends 50,000+. The session total approaches 1.5M tokens for a 30-turn session at $4.50.
- Three categories drive context growth: shell output (verbose by default), file reads (often duplicated across turns), and prior assistant responses (1,000-3,000 tokens each).
- The cost curve is nonlinear. A 25-turn session can cost 5x what an 8-turn session costs even when the work produced is similar.
- The benchmark measures the impact of context optimization at 20% on standard sessions, with 30-60% on heavy agentic sessions where redundancy is denser.
How Claude Code Accumulates Context
Every Claude Code API request includes the complete conversation history from turn 1, not just the latest message. The model needs the history to maintain coherent understanding across turns. The cost consequence is that the context window grows with every exchange, and earlier content is retransmitted on every subsequent request — a turn-3 file read pays its transmission cost on turns 4, 5, 6, all the way through the session's last turn.
Turn 1 sends roughly 1,000 tokens of context. Turn 5 sends 15,000. Turn 20 sends 50,000 or more. Each turn carries not just the new work, but the accumulated weight of everything before it.
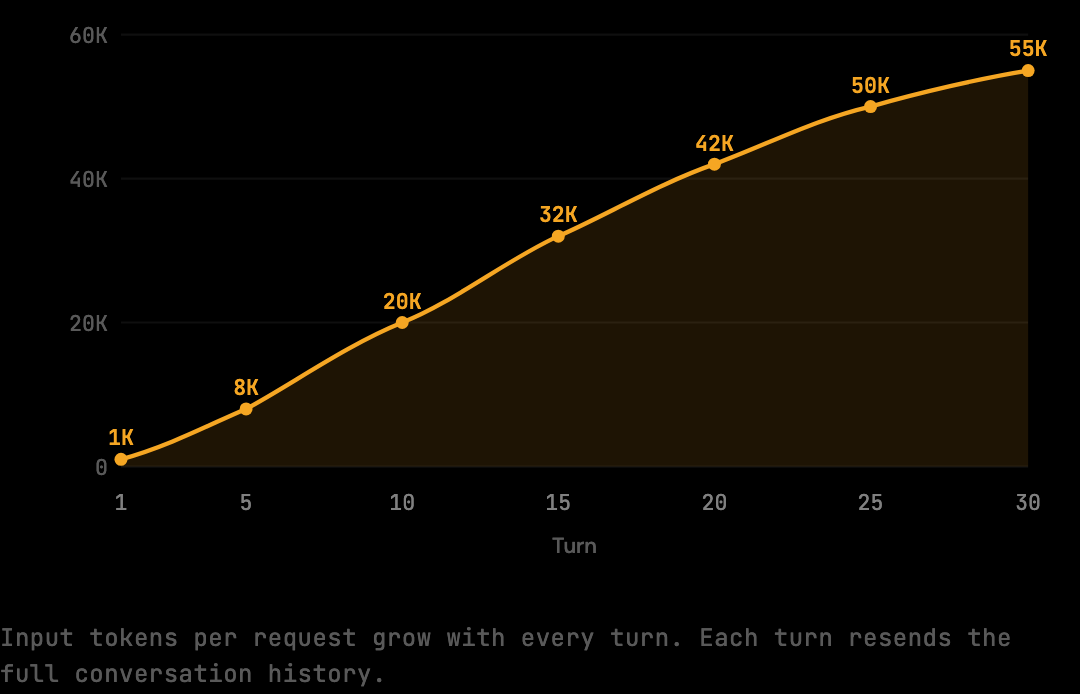
The Math Turns Against You
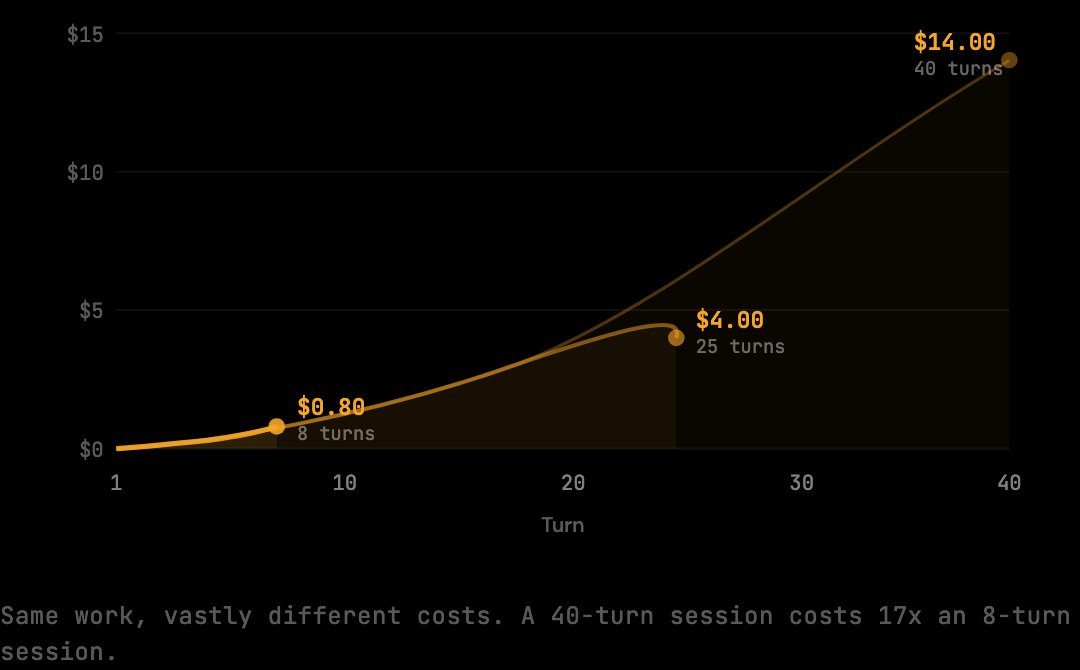
The cost structure of a Claude Code session is nonlinear. The first 10 turns of a 30-turn session cost roughly $0.45. The last 10 turns cost about $1.95. A 25-turn session can cost 5x what an 8-turn session costs even though the output produced is similar — the difference is the compounding context tail of the longer session.
Here is what a typical 30-turn session looks like in input tokens:
30 turns × 50,000 avg input tokens = 1,500,000 input tokens
1,500,000 × $3.00 / 1,000,000 = $4.50 per session
Two sessions a day, five days a week: $45. Add output tokens and longer sessions, and $200/month is not an edge case.
The key mechanic: by turn 20, you are paying for all prior context 20 times over. The tool result from turn 3, the file Claude read, the build output that came back, is being resent on turn 20 along with everything else. It was not expensive on turn 3. It has been expensive on every turn since.
This is why a session that produces roughly the same amount of code can cost dramatically different amounts depending on how long it runs. A task resolved in 8 turns might cost $0.80. The same task resolved in 25 turns (because of back-and-forth debugging, repeated tool calls, scope expansion) might cost $4.00. The code produced is similar; the context accumulated is not.
What Fills the Context Window
Three categories of content drive most context growth: shell output (often 20-40% of total context, verbose test runs and build logs), file reads (a 300-line file at 3,000 tokens, often appearing 3-4 times per session), and prior assistant responses (1,000-3,000 tokens each, accumulating across turns). Each gets retransmitted on every subsequent turn until the session ends.
Shell output. Every time Claude runs a build, test suite, or file listing, the full output enters the context. A passing test run across 44 test files produces hundreds of lines of output. What Claude needs from that output is the summary line: "44 suites, 312 tests, all passed." The preceding lines still cost tokens, and they are resent on every subsequent turn.
File reads. When Claude reads a file to understand it or modify it, the contents enter the context. Reading the same file multiple times across a session is common. Claude checks the current state before a change, then checks again after, then re-reads when a related question comes up several turns later. A 300-line file appearing three or four times adds 9,000-12,000 input tokens before accounting for the compounding resend effect.
Prior assistant responses. Claude's previous responses, with code, explanations, and proposed changes, accumulate in the context. Each response is typically 1,000-3,000 tokens. A 25-turn session might carry 30,000-50,000 tokens of prior assistant output that gets resent on every remaining turn.
Each of these categories contributes to the context. None of them shrinks on its own as the session continues.
Measuring What You Actually Pay
The compounding mechanic is directly measurable. The benchmark script runs the optimization pipeline against a corpus of realistic Claude Code session fixtures and reports raw versus optimized token counts. The difference (24,916 tokens on the standard corpus, 20% of 124,580) shows exactly how much of the input volume is removable redundancy versus essential signal.
Run it:
npx tsx scripts/benchmark.ts{
"reductionPercent": 20,
"rawTokens": 124580,
"optimizedTokens": 99664,
"model": "claude-sonnet-4-5",
"preset": "smart"
}rawTokens is what Claude Code would have forwarded to Anthropic without optimization, the actual token count of the full context windows, accumulated across all turns.
optimizedTokens is what reaches Anthropic after the pipeline runs.
The 24,916-token difference is not the result of removing anything critical. It is the result of trimming verbose shell output to its informational content, eliminating duplicate file reads, and collapsing redundant context that appeared in earlier turns. The model receives what it needs; the redundant transmission is eliminated.
What Context Optimization Actually Does
A token optimization proxy sits between Claude Code and Anthropic, intercepting each outgoing request, inspecting the context payload, applying optimizations (shell distillation, deduplication, tool result trimming), and forwarding a reduced payload to Anthropic. Tools like The Distillery implement this pattern. The setup is one environment variable and one install command. The reduction begins on the first request after activation.
npm install -g thedistillery
thedistillery startAfter those two commands, every Claude Code request routes through the proxy. No configuration, no prompt changes, no workflow adjustment required.
Each session that runs through the proxy cuts the accumulated waste that compounds turn by turn. The redundant shell output from turn 3 does not carry through to turns 15, 20, and 25. The file that was read three times appears once. The context that reaches Anthropic is smaller on every turn, especially the late turns where the compounding effect is largest.
The Compounding Math in Detail
A concrete walkthrough of the math: a turn-5 file read of a 3,000-token file does not pay $0.009 once. It pays $0.009 on turn 5, then $0.009 again on turn 6 when the full context resends, then $0.009 on turn 7, all the way through turn 30. The transmission cost of that single file read across the remaining 25 turns is $0.225 — 25x the direct cost.
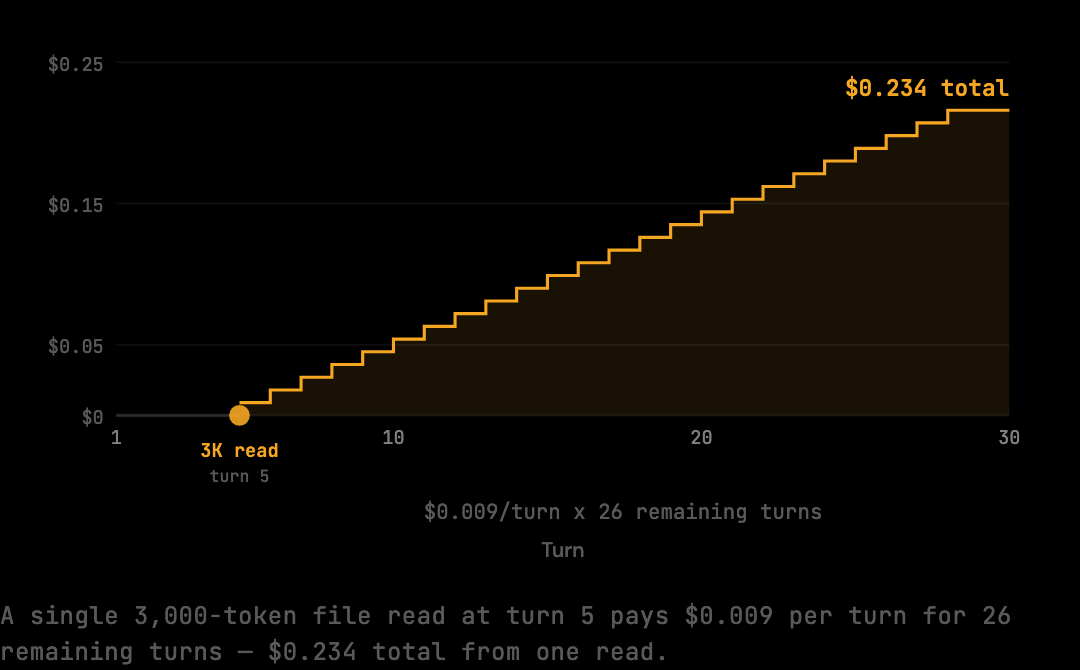
This is why even small re-reads matter. A 1,500-token shell output captured at turn 3 of a 30-turn session is transmitted 28 times in total: once when it is generated, then again on every subsequent turn. The cumulative transmission is 42,000 tokens — 28x the original capture cost.
The implication for cost reduction: removing waste early in a session has a much larger effect than removing waste late. A 1,500-token reduction at turn 3 saves 28 turns of retransmission. The same reduction at turn 28 saves only 2 turns. This is why context optimization at the proxy layer, applied to every request, compounds the savings the same way the original waste compounds the cost.
Why Restarting Sessions Cuts More Than Optimization Alone
Context optimization at the proxy layer reduces input volume per request but does not change the fundamental compounding mechanic. A 30-turn session is still structurally more expensive than two 15-turn sessions even with optimization, because the second 15 turns of a single session carry the accumulated weight of the first 15. Two separate 15-turn sessions each start fresh.
The combined approach of restarting sessions and applying optimization is what produces the largest cost reduction. Restarts cap the compounding tail; optimization reduces the per-request volume. A developer who applies both — short scoped sessions with the proxy active — typically pays 40-60% less than a developer who applies neither.
The discipline is workflow-based, not tooling-based: deciding when a task is "done enough" that the context can be discarded, restarting on a fresh branch when scope shifts substantially, treating long-running sessions as a code smell rather than a normal mode of operation. The proxy handles automation; restart discipline handles the structural cap.
What Different Session Lengths Actually Cost
The cost ratio between session lengths is not linear. A 10-turn session costs roughly $1.50 in input alone. A 20-turn session costs roughly $4 — 2.7x the 10-turn cost despite being twice as long. A 40-turn session costs roughly $14 — nearly 10x the 10-turn cost despite being 4x as long. The ratio worsens as sessions get longer because the compounding tail grows faster than the turn count.
This is the practical case for keeping sessions short. The cost difference between 10 turns and 40 turns is not 4x; it is closer to 10x. Workflows that naturally produce long sessions (extended debugging, multi-file refactors, exploratory reads across the codebase) generate disproportionate share of the bill, often 60-70% of monthly cost from 20-30% of total session count.
Frequently Asked Questions
Q: Why does my second session cost more than my first if I haven't changed how I work?
Each session is independent — the cost of session 2 is not affected by session 1. What varies between sessions is the work pattern: a session involving heavy shell commands, repeated file reads, or longer agentic exploration accumulates more context than a tightly scoped one. The "second session costs more" pattern usually reflects the second session being deeper or longer, not a model behavior change.
Q: Does restarting a session lose Claude's understanding of my project?
The model has no persistent memory between sessions; each session always starts fresh. Restarting "loses" only the immediate session history. Project-level context (your CLAUDE.md, system prompt, project instructions) is reloaded automatically on the new session. For most workflow boundaries, this is the desired behavior.
Q: Will Anthropic's prompt caching reduce the compounding cost?
Caching helps with static prefixes (system prompt, fixed instructions) but does not help with the part of the context that grows turn by turn, which is where most Claude Code volume sits. The cached portion is a single-digit percentage of total input tokens for a long Claude Code session. The compounding mechanic remains intact for the variable body of each request.
Q: Is the 20% benchmark figure realistic for my workflow?
The 20% is a floor on a representative corpus. Real sessions vary: tightly scoped sessions reduce by less, heavy agentic sessions reduce by 30-60%. The per-session log produced by the proxy reveals the actual figure for any specific workflow. Most developers see between 20% and 45% averaged across their normal session mix.
Q: How do I know if a session is getting expensive while it is still running?
The proxy logs each request's token count as it is processed. Watching the live count gives a real-time signal of how the context is growing. Most developers find that sessions become noticeably "heavy" around turn 15-20, when input volume per request crosses 30,000-40,000 tokens. That is a reasonable trigger to consider a restart for the next sub-task.
If you want to see the reduction in your own sessions, the proxy is a two-minute install.
Try it on your own Claude Code sessions.
The Distillery applies these distillations automatically. Free until it saves you something.