Why Claude Code Is So Expensive
Why Claude Code costs $10-50/day: every API turn re-sends the full session context. Where the money goes and how to cut it 30-60% at the proxy.
You set up Claude Code on a Monday. By Friday, you have a $180 API bill.
This is not a hypothetical. It is a pattern that repeats across developer communities every week. Someone integrates Claude Code into their daily workflow, starts getting real value from it, and then opens their Anthropic dashboard three weeks later to find a number that makes them pause.
The frustration is legitimate. And it deserves a real explanation, not "tokens add up," but a precise accounting of where the money actually goes. That is what this post is. By the end, you will understand the mechanics well enough to make real decisions about your usage.
TL;DR
- Claude Code bills through the Anthropic API at $3/M input tokens and $15/M output tokens. Every turn re-sends the full conversation context.
- A typical 30-turn session accumulates 1.5M input tokens. At $3/M that is $4.50 per session, or roughly $200/month at two sessions per day.
- Shell output, duplicate file reads, and verbose tool results drive most of the input volume. None of them shrink as the session grows.
- Manual mitigations (narrow scope,
.claudeignore, specific prompts) help. Automated context optimization at the proxy layer produces 30-60% cost reduction depending on session patterns, with a 20% conservative deterministic benchmark floor and no workflow change. - Heavy sessions with repeated tool calls and long file reads see the higher end of the 30-60% range because they have more redundancy to remove.
Where Your Tokens Go
Claude Code's billing comes down to one core mechanic: every API request re-sends the full conversation context. By turn 20 of an active session, that payload routinely reaches 50,000 to 100,000 input tokens per request. At $3 per million input tokens, a single 30-turn session bills around $4.50 before output tokens are counted at $15 per million.
As of April 2026, Claude Sonnet pricing is:
- Input tokens: $3.00 per million
- Output tokens: $15.00 per million
A "token" is roughly 4 characters of text, about 0.75 words. So 1 million tokens is approximately 750,000 words, or about 10 average novels.
That sounds like a lot. The problem is how fast a coding session accumulates context.
A typical turn might include:
- Your current message: ~200 tokens
- Claude's previous response (with code): ~2,000 tokens
- A tool result (file read, shell output): ~5,000 tokens
- All prior turns: accumulating with each exchange
The math on that is direct:
30 turns × 50,000 avg input tokens = 1,500,000 input tokens
1,500,000 × $3.00 / 1,000,000 = $4.50 per session
Two sessions a day, five days a week: $45. Add output tokens and the occasional long session, and $200/month is not an edge case.
The Real Cost Drivers
Not all context is equal. In a typical 30-turn coding session, three categories of content account for the bulk of the input volume: shell output (often 20-40% of total context), duplicate file reads (a single 300-line file can appear three or four times across a session), and verbose tool results (full stack traces, complete directory listings). All of them inflate the payload that is resent on every subsequent turn.
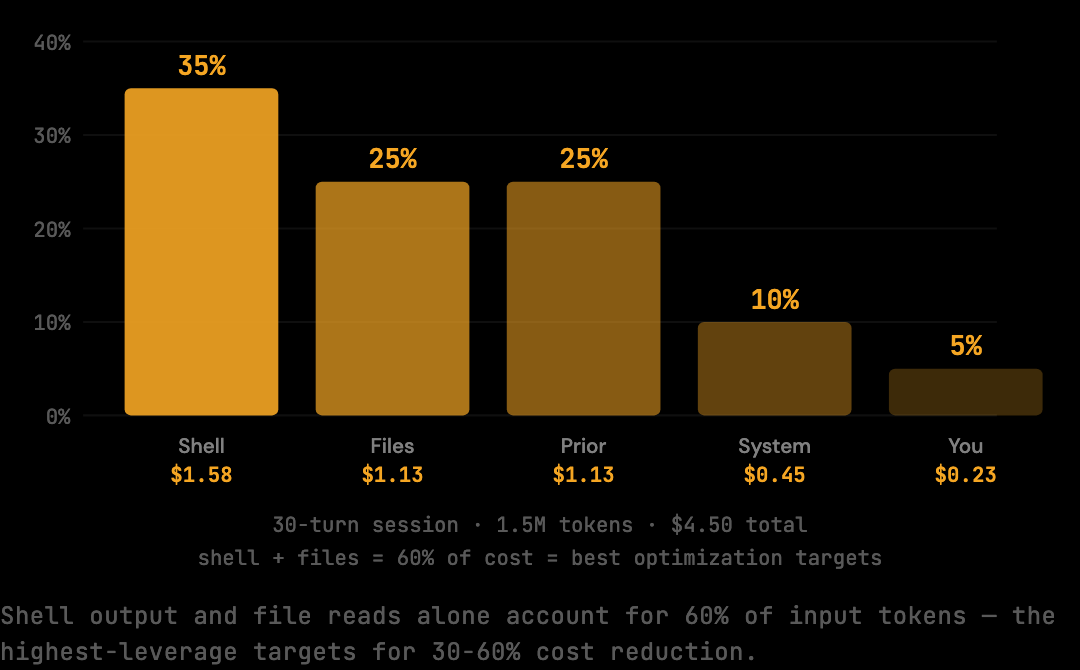
Shell output is the biggest culprit. When Claude Code runs a build, test suite, or file listing, the full output goes into the context. Consider what a typical test run looks like:
PASS src/auth/login.test.ts (2.3s)
PASS src/api/routes.test.ts (1.8s)
PASS src/db/queries.test.ts (3.1s)
PASS src/utils/format.test.ts (0.9s)
... (40 more test files)
PASS src/components/Button.test.ts (0.4s)
Test Suites: 44 passed, 44 total
Tests: 312 passed, 312 total
Snapshots: 0 total
Time: 28.4 s
What Claude actually needs from that output: "44 suites, 312 tests, all passed." The rest is noise that still costs tokens.
Duplicate file reads compound this. When you ask Claude to edit a file, it reads the current version. If you ask for a related change two turns later, it reads the file again. The same 300-line file can appear in your context three or four times across a session.
Tool result verbosity adds another layer. Full stack traces, complete directory listings, and entire file contents get added to context even when only a few lines are relevant to the current task.
The cumulative effect: by mid-session, a substantial portion of your input tokens is content that has already been processed, is largely redundant, or contains more information than the task requires.
Why the Bill Compounds Mid-Session
The cost of a Claude Code session is not distributed evenly across turns. The first ten turns of a typical session bill around $0.45 in input tokens. The last ten turns of the same session bill closer to $1.95, more than four times as much, because each of those turns carries the accumulated weight of everything that came before.
This is the nonlinear cost curve that surprises most developers. A turn-3 file read does not cost 3,000 tokens once. It costs 3,000 tokens on turn 3, then 3,000 more on turn 4 when the full context resends, then 3,000 more on turn 5, all the way through turn 30. A single re-read at turn 8 of a 30-turn session pays its 3,000-token transmission cost 23 times.
The implication for cost reduction: the cheapest way to cut a Claude Code bill is to keep sessions short. Not because the work itself is more expensive, but because the compounding tail of a long session contains most of the cost.
What You Can Do About It
There are practical steps that reduce costs without changing how you work. Manual techniques (narrow scope, .claudeignore, specific prompts) cut waste at the source. Automated context optimization runs at the proxy layer and cuts waste before it reaches Anthropic. Both can be combined.
Start sessions with a narrower scope. Instead of opening Claude Code on your entire project, open it in a specific directory or with a specific task framing. Shorter, focused sessions accumulate context more slowly.
Use .claudeignore for large assets. Add a .claudeignore file to your project root to prevent Claude Code from reading build artifacts, lock files, and generated directories. This reduces the cost of any file-listing or search operation.
Be specific in your requests. Vague requests generate more tool calls. "Fix the auth bug" triggers more exploration than "The login function in src/auth/session.ts is not invalidating tokens on logout."
Use a token optimization proxy. A proxy sits between Claude Code and the Anthropic API, intercepts each request, applies optimizations to the context, and forwards the reduced payload. Your workflow is unchanged. You set one environment variable. Tools like The Distillery implement this pattern and report 30-60% cost reduction depending on session patterns, with a 20% conservative benchmark floor on a reproducible corpus.
npx tsx scripts/benchmark.ts{
"reductionPercent": 20,
"model": "claude-sonnet-4-5",
"preset": "smart"
}That is the 20% conservative deterministic benchmark floor on the corpus. Real-world sessions see 30-60% cost reduction depending on session patterns — sessions with heavy shell output or repeated file reads see the higher end because the optimization has more to work with.
The Compounding Problem
Claude Code is expensive for a structural reason: the compounding context window. Every turn resends everything. That is how the model maintains coherent memory across a session, and it is the right tradeoff for quality. But it means costs scale nonlinearly as sessions grow longer.
Understanding this mechanic changes how you interpret your bills. The cost is not primarily from a single expensive operation. It is from many mid-session turns, each carrying the accumulated weight of everything before them.
The first step to reducing costs is knowing exactly what you are paying for. Once you can name where the input tokens are going (shell output, duplicate file reads, prior assistant responses), the optimization choices become concrete rather than abstract.
What This Means for Long Sessions
A four-hour debugging session is not just a longer version of a one-hour session. It is structurally more expensive per turn, because every turn carries the accumulated history of the previous turns. By turn 50, the input payload routinely exceeds 80,000 tokens per request, and the per-turn cost approaches $0.30 in input alone.
The most expensive sessions developers report (>$10 in a single afternoon) almost always involve one of three patterns: agentic refactors that touch many files, debugging across multiple subsystems where Claude re-reads configuration files repeatedly, or exploratory sessions where the developer keeps adding scope without restarting context.
Recognizing the pattern matters more than mitigating it case by case. A developer who restarts context on a fresh branch when they pivot to a new sub-task pays substantially less over a working day than a developer who keeps a single session alive for everything. The cost difference compounds across an entire month of usage.
How to Verify the Reduction
Reading about a 30-60% cost reduction is one thing. Confirming the same reduction applies to your own sessions is another. Two checks, one before optimization is active and one after, give you the actual delta on your workflow rather than a benchmark average.
The first check is the benchmark itself, which runs the optimization pipeline against a fixed corpus of multi-turn coding fixtures and reports raw versus optimized token counts. It is reproducible and exits with a percentage that does not depend on your sessions. This sets your floor.
The second check is a per-session log. After running real Claude Code sessions through a token optimization proxy, the per-session breakdown reports raw token count and optimized token count for each session, with the difference shown in absolute tokens and as a percentage. Sessions with heavy shell output or repeated file reads typically show 30-60% reductions; lean sessions with mostly conversational turns show closer to the 20% benchmark floor.
Together they give you both the reproducible baseline and the workflow-specific number, which is the one that determines how much of your bill the optimization actually removes.
Frequently Asked Questions
Q: Why is Claude Code more expensive than ChatGPT or Cursor?
ChatGPT and Cursor Pro are flat subscriptions. Claude Code is a thin client over the Anthropic API, billed per token. Because each turn resends the full conversation context, a 30-turn coding session can accumulate 1.5 million input tokens. At $3 per million, that is $4.50 per session, with no monthly ceiling.
Q: Does using Claude Haiku instead of Sonnet fix the problem?
It reduces the per-token cost but not the accumulation. The same 1.5 million tokens are still transmitted on Haiku, just at a lower rate. The structural problem (every turn resending the full context) is identical across models. Switching from Sonnet to Haiku saves money on the same volume; it does not reduce the volume.
Q: Will Anthropic prompt caching reduce my bill?
Anthropic's prompt caching reduces cost on repeated static prefixes (system prompts, fixed instructions). It does not help with the part of the context window that grows turn by turn, which is where most Claude Code volume sits. Caching is useful at the edges; it does not change the compounding mechanic.
Q: How long does it take for the optimization to start saving money?
The reduction is per-request, so it begins on the first request after you set ANTHROPIC_BASE_URL to point at the proxy. There is no warmup period or learning phase. Whatever the benchmark percentage is on your session patterns is the percentage you save starting immediately.
Q: Does context optimization affect Claude's response quality?
The optimization stages remove redundant content (duplicate file reads, verbose shell output formatting, stale tool results) without removing semantic content. A test summary "44 suites passed" carries the same information as 200 lines of per-test output. Claude's understanding of the result is identical, so the response is unaffected.
If you are ready to start reducing your bill now, The Distillery gets you 30-60% cost reduction depending on session patterns (20% conservative benchmark floor) with a two-minute setup.
Try it on your own Claude Code sessions.
The Distillery applies these distillations automatically. Free until it saves you something.