What Is Context Engineering? (Why It's the Biggest Driver of Your AI Bill)
80-90% of your Claude Code bill is context you didn't need to send. Context engineering is how you fix that — four levels, only one is hands-off.
The biggest line on your Anthropic bill is not the output. It's the context you didn't need to send.
Most developers focus on the output side when thinking about API costs, specifically how many tokens Claude generates and how long its responses are. Output tokens are more expensive per unit. But input tokens are where the volume is. And input tokens are where the waste accumulates.
Context engineering is the practice of deliberately managing what goes into the context window: what enters, what stays, and what gets removed before the request reaches the model. Most developers never think about it. It is the most direct lever on your API bill.
TL;DR
- Context engineering is the practice of managing what enters, stays in, and exits the context window between turns of an AI session.
- For Claude Code, 80-90% of the bill is input tokens, and most of that volume is repeated content from earlier turns.
- The four levels are session scoping, exclusion rules, context pruning, and automated distillation. Only the last is hands-off.
- Automated distillation at the proxy layer produces 30-60% cost reduction depending on session patterns, with a 20% conservative benchmark floor on standard sessions.
- Output-focused fixes (shorter responses, switching to Haiku) discount the waste; they do not eliminate it.
What Goes Into the Context Window
The context window for a single Claude Code request is not just your latest message. It is a complete record of the session: every prior message, every tool result, every file read, plus the system prompt. By the middle of a working session, the messages array can hold 30,000 to 50,000 tokens. Most of that content arrived in earlier turns and is being retransmitted in full.
Every Claude API request includes a messages array. For a Claude Code session, that array grows with every turn:
- Your current message
- All prior messages in the session (yours and Claude's)
- Tool call results (file reads, shell output, search results)
- Any system prompt or project instructions
The model has no persistent memory; it can only work with what is in the window right now. You are not just paying for the conversation you are having — you are paying for every conversation you had earlier in the session, retransmitted in full.
Three sources of context volume that developers routinely underestimate: tool results, system prompts, and file reads. Tool results are the most expensive category — a single ls -R on a large monorepo can return tens of thousands of tokens, and that result persists in the context for every subsequent turn. System prompts (project instructions, CLAUDE.md files, injected preambles) are re-sent on every request even though their content rarely changes, adding a fixed overhead that compounds across long sessions. File reads accumulate silently: every time Claude reads a file to answer a question, that file's content enters the context and stays there until the session ends or the context is explicitly reset. A developer who asks Claude to check five config files early in a session is carrying those five files on every subsequent API call for the rest of the session.
Why Most Developers Ignore It
Context engineering is invisible. There is no dashboard showing what percentage of your current request is redundant content. The Anthropic dashboard reports total input tokens but says nothing about composition. The natural reaction to a high bill is to look at output (shorter responses, fewer tool calls) or switch to a cheaper model. Both miss the input volume problem entirely.
Switching from Sonnet to Haiku costs a fraction per token, but if the same 1.5 million tokens are accumulating in the context window, the compounding is just discounted, not eliminated. You spend less per redundant token, not fewer redundant tokens.
Context engineering addresses the root cause.
What Context Engineering Looks Like
In practice, context engineering operates at four levels, each addressing a different stage of the context lifecycle. Session scoping decides what enters; exclusion rules block known noise; context pruning removes content that has served its purpose; automated distillation handles redundancy at the proxy layer. The first three require active developer attention; the fourth runs without intervention.
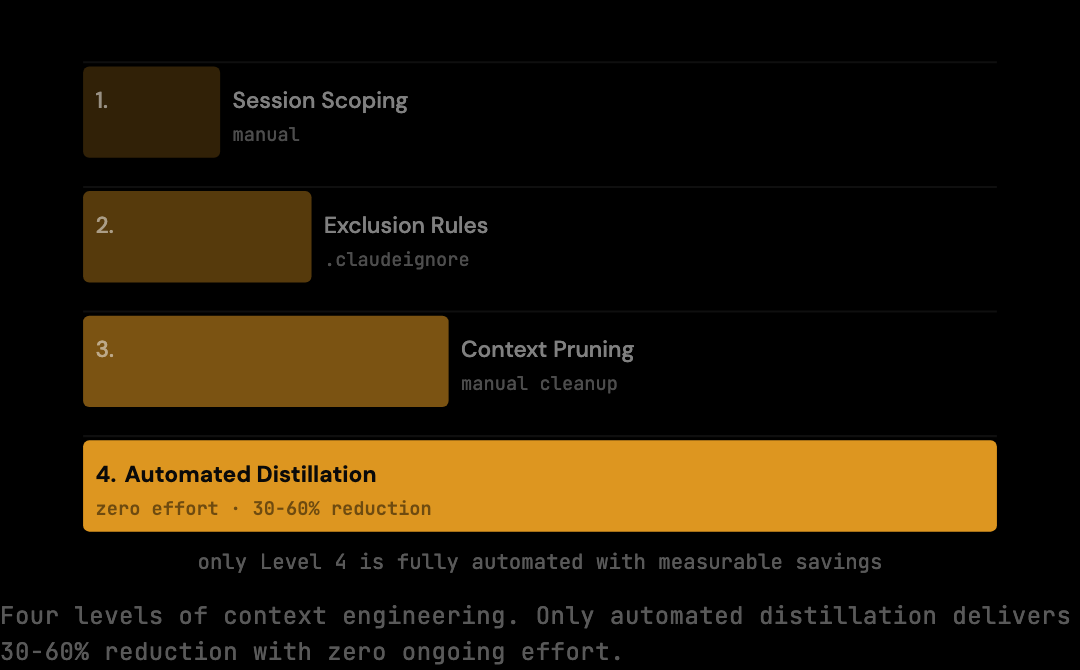
Session scoping, deciding what enters the session at all. A tightly scoped session on a single module accumulates less irrelevant context than a session that ranges across the entire codebase. Each file read, each tool result, each exploratory exchange that does not directly serve the current task adds tokens to every subsequent request.
Exclusion rules, defining what the model should not be able to read. A .claudeignore file prevents large generated files, lock files, and build artifacts from entering the context even when Claude Code tries to read them. This limits the surface area for accidental context inflation.
Context pruning, removing content that has served its purpose. A file read from fifteen turns ago that is no longer relevant to the current task is still in the context window, adding tokens to every request. Manually managing this is difficult, as you would need to know what Claude has processed and what remains useful.
Automated distillation, the approach with the most consistent impact. A proxy that sits between your tools and the API can analyze the context before each request and strip redundant content: duplicate file reads collapsed to one, verbose tool outputs summarized to their useful portions, stale turns trimmed from long sessions. Tools like The Distillery implement this pattern: the model receives a smaller but complete context, and you pay for less.
The Numbers
Context engineering produces measurable savings. Real-world cost reduction is 30-60% depending on session patterns; on the standard Claude Code benchmark corpus, the conservative deterministic floor is 20% of input tokens. On heavy agentic sessions with repeated tool calls and large file reads, the same pipeline achieves the higher end of the 30-60% range. At $3 per million input tokens on Sonnet and 1.5 million tokens per typical 30-turn session, that translates to $0.90 saved per standard session and $1.50-$2.70 saved per heavy session.
The impact of context engineering depends on session patterns. Shorter, focused sessions have less distillable content, as there is less redundancy to remove. Longer agentic sessions with repeated tool calls, multi-file edits, and extended debugging accumulate significantly more.
At $3.00 per million tokens on Sonnet:
Standard session: 1.5M tokens → 1.2M after 20% reduction → $0.90 saved/session
160 sessions/mo: $144/month saved
For teams running multiple developers simultaneously, the savings scale with headcount.
The Automation Case
Manual context engineering reduces costs but requires every developer to remember it on every session. Realistic adherence rates inside a team are below 50%, and the rules degrade further over time. Automated distillation runs at the infrastructure layer and applies to every request without developer attention. The savings are continuous and predictable rather than dependent on individual discipline.
Manual vs Automated: When Each Applies
The two approaches are complementary, not alternatives. Manual context engineering produces the largest savings when applied to session boundaries: deciding what scope to open, when to restart, and what to exclude. These are decisions a tool cannot make for the developer because they require knowing the intent of the work. A tightly scoped session is structurally cheaper than a loosely scoped one, and no proxy can change that.
Automated distillation produces the largest savings within an active session, where redundancy accumulates in ways the developer cannot easily manage. Once Claude has read a file three times, the developer has no clean way to instruct the model to "only count the first read." The proxy can detect duplicate content programmatically and elide subsequent appearances before the request leaves the machine.
The practical division of labor: the developer makes scope decisions; the proxy handles redundancy. Together they produce a compound reduction larger than either alone, because they target different sources of waste.
What Context Engineering Does Not Mean
Context engineering is not prompt engineering. Prompt engineering is about wording: choosing instructions that produce better outputs from the model. Context engineering is about volume: choosing what goes into the input window in the first place. The two operate on different parts of the request and address different problems.
It is also not memory management in the sense of vector databases or retrieval-augmented generation. Those techniques inject relevant content from outside the conversation. Context engineering manages content that is already inside the conversation and decides which parts of it the model needs to see again.
Confusing the two leads to suboptimal interventions. Improving prompt wording does not reduce input volume. Adding a vector database does not remove redundant tool results. The lever for input cost is what enters and persists in the window, which is the specific domain context engineering addresses.
Frequently Asked Questions
Q: Is context engineering the same as prompt engineering?
No. Prompt engineering optimizes the wording of instructions to improve model output. Context engineering optimizes what enters the context window in the first place to reduce input volume. They operate on different parts of the request: prompt engineering on the user message, context engineering on the entire messages array including prior turns and tool results.
Q: Can I do context engineering without a proxy tool?
Partially. Manual techniques (tight session scoping, .claudeignore files, disciplined session restarts when scope shifts) reduce input volume without any tooling. They cannot deduplicate file reads or distil shell output, which is where the largest waste lives. A proxy automates the parts that manual practice cannot reach.
Q: Does context engineering work for ChatGPT or Gemini?
The principle applies to any LLM API where context is retransmitted on each turn, which is most of them. Implementations vary: Claude Code's mechanic of resending the full conversation history is similar to OpenAI's Assistants API and Google's Gemini coding workflows. The 30-60% real-world range (with a 20% conservative deterministic floor) is specific to Claude Code's session patterns, but the underlying logic transfers.
Q: Will context engineering break Claude's ability to remember earlier turns?
No, when done correctly. The distillation removes redundant transmission, not semantic content. A file read three times in the same session can be transmitted once and referenced thereafter. The model still has access to the file content because it is in the context. The duplicates are eliminated before the request reaches Anthropic. Claude's behavior is unchanged.
Q: What is the typical savings from context engineering on a personal Claude Code workflow?
For a developer running two sessions per day, savings are roughly $36/month at the 20% conservative benchmark floor, and $80-$150/month at the 30-60% real-world range on dense sessions. The exact number depends on session patterns.
If you want to understand what your current sessions are actually costing and see what the distillation numbers look like on a realistic benchmark, the Claude Code API pricing page has the full breakdown by model and session pattern.
Try it on your own Claude Code sessions.
The Distillery applies these distillations automatically. Free until it saves you something.