The Same File Read 4 Times: How Claude Code Compounds Token Costs
Claude re-reads package.json 4x per session. A 3,000-token file becomes 12,000 tokens billed, then compounds further. Why, and how to fix it.
Claude read your package.json 4 times this session. You paid for it 4 times.
This is not a bug. It is how the model works, and it is one of the most direct ways coding sessions accumulate token costs faster than the work being done would suggest.
TL;DR
- LLMs have no memory between tool calls. Claude re-requests files when in doubt because re-reading is the safer judgment.
- A 300-line
package.jsonat 3,000 tokens, read 4 times, adds 12,000 tokens of direct cost — and far more after the compounding effect. - The compounding effect: a re-read at turn 8 of a 30-turn session resends those tokens 22 more times. The transmission cost is multiplied, not paid once.
- Configuration files (
package.json,tsconfig.json, schema files, entry points) are the most common re-read victims because they apply to many tasks. - Deduplication at the proxy layer detects repeated content and replaces subsequent appearances with references, eliminating the redundant transmission.
Why Claude Re-Reads Files It Already Has
LLMs have no persistent memory between tool calls. When Claude reads package.json at turn 2, the contents enter the context window. By turn 8, the working memory has shifted to other files and decisions. Rather than reason about whether the file content is still current, the safer judgment is to re-read. Each individual re-read is reasonable; the aggregate over 30 turns is not.
This happens most often with configuration files and entry points.
package.json gets read to check dependencies, then again to verify the scripts section, then again when a build error references it, then again during a refactor that touches project structure.
Each read is individually reasonable.
The aggregate is not.
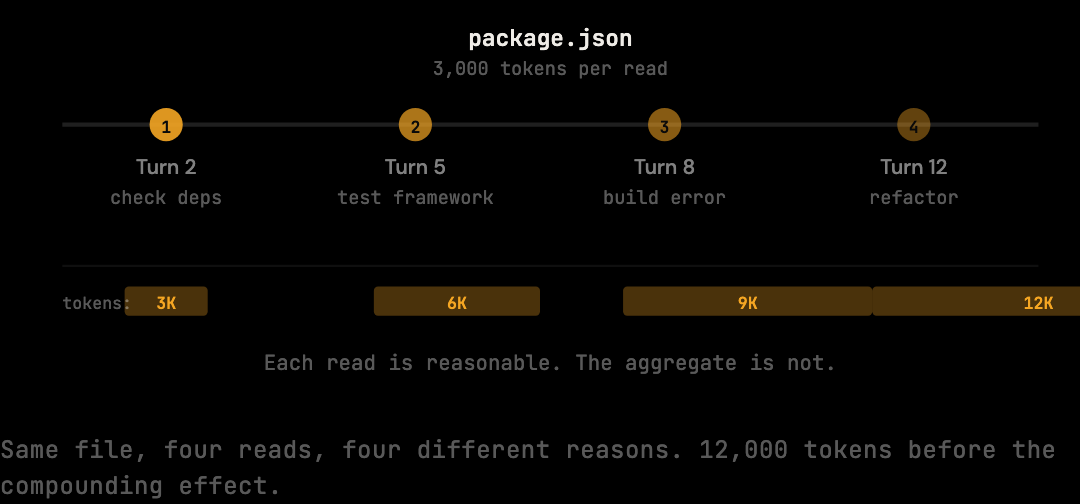
The same pattern applies to tsconfig.json, schema files, environment configs, and the main entry point.
These are the files Claude returns to most often because they are relevant to the widest range of tasks.
They are also the files most likely to be read multiple times across a session.
What a Re-Read Actually Costs
A 300-line package.json is roughly 3,000 tokens. Reading it 4 times adds 12,000 input tokens — $0.036 at Sonnet's $3 per million input rate. That sounds small in isolation, but coding sessions involve multiple files, and each file accumulates the same way. A realistic session with several configuration files compounds quickly to $0.16 per session in duplicate reads alone.
A realistic session with several large source files might look like this:
package.json read 4 times = 12,000 tokens
tsconfig.json read 3 times = 6,000 tokens
prisma/schema.prisma read 3 times = 15,000 tokens
src/index.ts read 5 times = 20,000 tokens
Total duplicate reads: ~53,000 tokens = $0.16 in one session
Across 20 sessions per week, duplicate file reads alone can account for $3.20 per week, or roughly $166 per year, before the compounding effect is applied.
And there is a compounding effect.
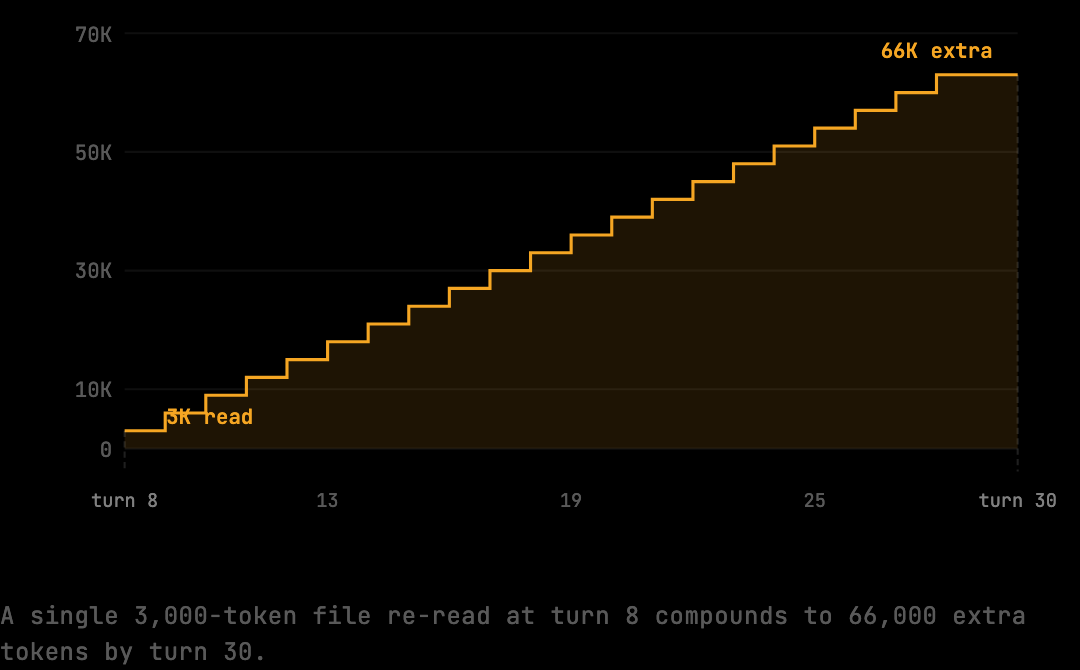
The Compounding Effect Across a Session
The cost of a re-read is not paid once. Because every turn resends the full conversation context, a file re-read at turn 8 is not just billed on turn 8 — its content is resent on turns 9, 10, 11, all the way through the session. A 3,000-token re-read in a 30-turn session multiplies into 66,000 additional tokens of compounding transmission cost.
This is why duplicate file reads are disproportionately expensive compared to what a simple token count would suggest. The file read a third time at turn 8 is not 3,000 tokens of overhead — it is 3,000 × (turns remaining) tokens of overhead, where every subsequent turn carries that payload to Anthropic.
What the Pattern Looks Like in Practice
A concrete 8-turn example: a developer asks Claude to add a new dependency. Claude reads package.json at turn 2 to check current dependencies. The developer asks for a related test update. Claude reads package.json again at turn 5 to check the testing framework version. A build error appears. Claude reads tsconfig.json and package.json again at turn 8 to correlate the error with project configuration. By turn 8, package.json has appeared three times, each appearance carrying the full 3,000-token payload. Turns 9 through 30 carry all three copies on every request.
The benchmark measures this directly:
npx tsx scripts/benchmark.tsThe benchmark corpus includes sessions with repeated file reads, which is one of the core patterns the deduplication stage targets.
The rawTokens figure reflects the full context payload including duplicates; optimizedTokens reflects what remains after deduplication runs.
Deduplication as the Direct Counter
Context deduplication addresses this pattern directly. When the same file content appears multiple times in a context window, subsequent appearances are replaced with a compact reference and the first occurrence is preserved. The model still has access to the content; the duplicate transmission is eliminated before the request reaches Anthropic. From Anthropic's perspective, the file appears once. From Claude's perspective, the behavior is unchanged.
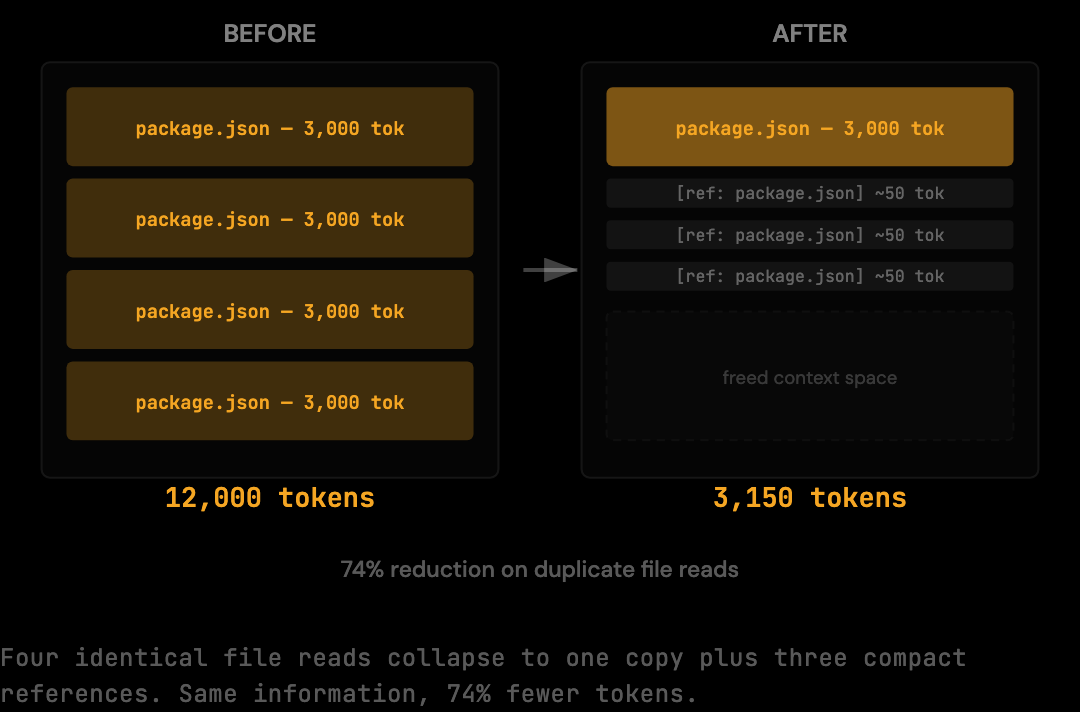
Tools like The Distillery implement this deduplication at the proxy layer. The proxy detects that the file content is already present in the context and removes the redundant copy before forwarding. Claude can re-request files as often as it needs to; the deduplication runs after the model decides what to request, not before.
npm install -g thedistillery
thedistillery startAfter setup, every Claude Code request routes through the local proxy. Deduplication runs on each request before forwarding to Anthropic.
Why the Model Cannot Be Asked to Stop Re-Reading
A reasonable question: can Claude just be instructed to remember files it has already read? The answer is no, in any robust way. The model has no internal state between tool calls. When deciding whether to re-read, it operates only on what is currently in the context window. The decision to re-read is itself a function of the context state, and modifying it from outside the model would require constraining tool use in ways that would degrade the agent's ability to handle edge cases.
A system prompt instruction like "do not re-read files you have already seen" sometimes works for short sessions but fails over long ones. The model loses track of what it has read as the context grows and earlier reads scroll into the middle of a long history. Claude cannot reliably search its own context window for prior file reads while also performing the current task. The result is inconsistent compliance — the model sometimes obeys, sometimes does not, and there is no way to enforce the rule.
Deduplication at the proxy layer sidesteps the problem entirely. The model decides whether to re-read using its normal judgment. The proxy detects the duplicate after the fact and elides it before the request leaves the machine. The model's behavior is unchanged; only the transmission is optimized.
Which Files Get Re-Read Most Often
In a typical Claude Code session, the most frequently re-read files are the ones that apply to multiple tasks. Configuration files top the list because they encode decisions that affect many parts of the codebase. package.json is read to check dependencies, build scripts, peer dependencies, and engine constraints — four distinct reasons that surface across different turns of the same session.
tsconfig.json is similar: it gets read to check paths aliases, target and module settings, strict flags, and reference structures. Schema files (prisma/schema.prisma, GraphQL schemas, OpenAPI specs) are read repeatedly because they define types used across the entire codebase. Entry points (src/index.ts, app.ts, main.py) are read because they reveal application structure that informs many decisions.
The pattern is not random. The files that are most useful are the files that are most reused. The proxy's deduplication stage targets exactly this distribution: any file content that appears more than once gets compressed to a reference after the first appearance, regardless of how many times the model decides to re-request it.
How to Measure Re-Read Cost in Your Own Sessions
The benchmark figure (20% on the standard corpus) does not break down the contribution of duplicate reads specifically. To see how much your sessions are losing to re-reads, the per-session log produced by the local proxy reports raw and optimized token counts for each session. The difference attributed to deduplication versus other stages reveals the share that re-reads contribute to your bill.
Sessions with heavy iteration on the same files (refactors, debugging, feature builds) show larger deduplication shares. Sessions with primarily exploratory reads (different files, each read once) show smaller shares. For most developers running multi-turn coding sessions, deduplication contributes a meaningful fraction of the overall reduction — typically 5-15% of input tokens depending on workflow patterns.
Frequently Asked Questions
Q: Why does Claude re-read instead of caching the file content itself?
The model has no persistent state between API requests. Each request is independent, and the model can only reason about what is in the context window of the current request. Re-reading is the safe default when the model is uncertain whether prior content is current. The judgment call happens inside the model and cannot be constrained from outside without breaking other behavior.
Q: Does deduplication change what Claude sees in the context?
The deduplicated content is replaced with a compact reference to the first appearance. The model can still resolve the reference to the original content because the original is preserved. Functionally, Claude has access to the same information; only the transmission is shortened. Output behavior is unchanged.
Q: How much do duplicate reads contribute to a typical bill?
Roughly 5-15% of input tokens in standard Claude Code sessions, depending on workflow. Sessions with heavy iteration on the same files contribute more. Lean exploratory sessions contribute less. The benchmark's 20% reduction includes deduplication plus other stages (shell output distillation, tool result trimming).
Q: Will deduplication work for files that have been edited between reads?
The deduplication uses content hashing, so two reads of the "same" file with different content (for example, after Claude edits it) are treated as distinct. The first version is preserved as-is, and the edited version is preserved as-is. Both appear in the context. Only identical content is collapsed.
Q: Can I see which files my sessions are duplicating most?
Yes. The per-session stats reported by the proxy include a breakdown by stage, which surfaces deduplication-specific savings. The detail shows total bytes deduplicated per session. Sessions where deduplication contributes a large fraction tend to have a small number of files being read repeatedly.
The file re-reads do not disappear from your sessions. Claude still requests the same files when it needs them. What changes is how those re-reads are counted at the billing layer. A proxy with content deduplication catches duplicate file reads before they reach Anthropic, which means you stop paying for the same content on turn 9, 12, 15, and 22.
Try it on your own Claude Code sessions.
The Distillery applies these distillations automatically. Free until it saves you something.