How The Distillery Reduces Claude Code Bills: A Technical Deep Dive
Local Fastify proxy intercepts Claude Code, runs five distillers, forwards smaller payload to Anthropic. 30-60% cost cut, source on GitHub.
If a tool sits between your API requests and Anthropic, you should understand exactly what it does. This post opens the hood on The Distillery: how it intercepts Claude Code's requests, what it does to the message payload, why the model's responses are unaffected, and how you can verify all of it yourself.
No black boxes. The source is on GitHub.
TL;DR
- The Distillery is a local Fastify HTTP server that runs on
localhost:3080and forwards Claude Code requests toapi.anthropic.comafter applying optimizations. - Five distillers run on each request: log distillation, diff (deduplication), smart array sampling, search re-ranking, and code distillation.
- Each distiller targets a specific source of redundancy in Claude Code sessions. Real-world cost reduction is 30-60% depending on session patterns; the conservative deterministic benchmark floor is 20% on the standard benchmark corpus.
- Output is unaffected because the distillers remove redundant transmission, not semantic content. A test result "44 suites passed" is unchanged whether expressed in 1 line or 200.
- Three verification paths: run the benchmark, check per-session stats with
thedistillery stats, or read the source code directly on GitHub.
Architecture: A Local Proxy
The Distillery runs as a local HTTP server on port 3080, built on Fastify. When you run thedistillery start, it writes ANTHROPIC_BASE_URL=http://localhost:3080 into ~/.claude/settings.json, which reroutes Claude Code from api.anthropic.com to the local proxy. The proxy inspects each request body's messages array, applies the optimization pipeline, and forwards the modified request to Anthropic using the existing API key. No keys leave the machine in any non-standard way.
Every request endpoint Claude Code uses — messages, completions, streaming — passes through the proxy before reaching Anthropic.
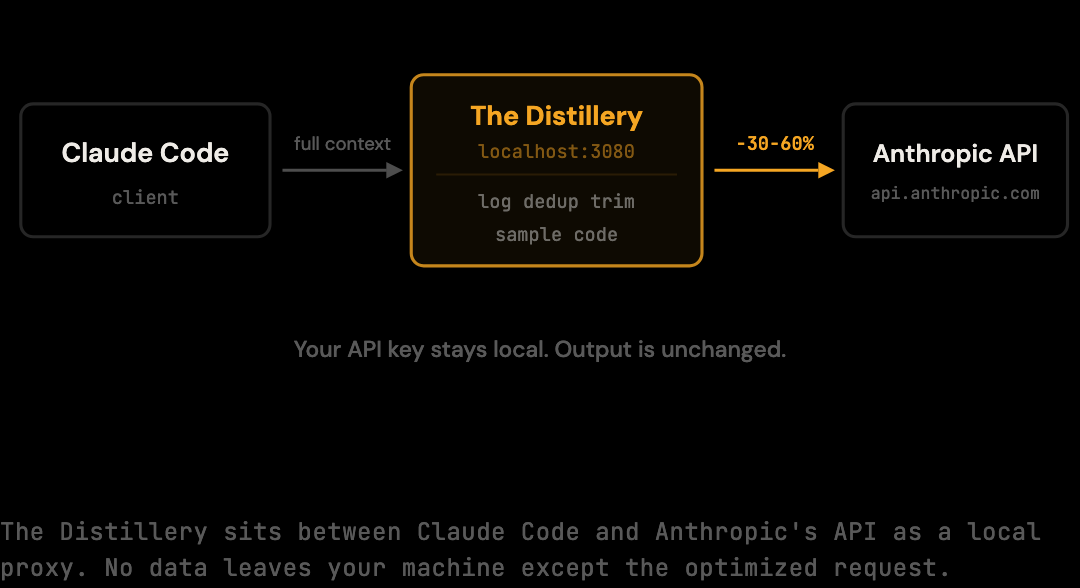
The flow looks like this:
Claude Code -> The Distillery (localhost:3080) -> api.anthropic.com
|
optimize input tokens
(output unchanged)
A few things worth noting explicitly:
Your API key never leaves your machine in a way that differs from normal usage. The proxy forwards it in the Authorization header of the outbound request, the same way Claude Code would. The proxy does not store it, log it, or transmit it anywhere else.
The proxy only modifies input. Claude's response is streamed back from Anthropic byte-for-byte. No modifications, no buffering beyond what streaming requires. If the model says something, you see it.
Zero configuration required. The proxy reads no config file by default. One environment variable, and it works.
The Distillation Pipeline
The 30-60% real-world cost reduction (depending on session patterns) comes from five distillers applied sequentially to each request's messages array. Each distiller targets a specific content type that appears in Claude Code sessions: log distillation handles shell output, diff distillation deduplicates repeated content, smart distillation samples large arrays, search distillation re-ranks code search results, and code distillation handles large code blocks. The pipeline is deterministic and fail-safe. The 20% deterministic benchmark floor is measured in our benchmark (npx tsx scripts/benchmark.ts).
1. Log Distillation (src/optimization/compressors/log.ts)
Build logs, test output, and shell command results are the largest source of redundant tokens in typical coding sessions. They contain timestamps, ANSI escape codes, progress indicators, and repeated file paths, content that carries near-zero informational value for the model's next response.
The log distiller identifies tool result blocks that contain terminal output, strips ANSI sequences, collapses repeated patterns, and preserves error messages, final summary lines, and failure context. A 200-line test run output typically distils to 3-5 lines while retaining all the information Claude needs to understand what passed and what failed.
2. Diff Distillation (src/optimization/compressors/diff.ts)
When Claude reads a file early in a session and that same file appears again several turns later, the full content is being retransmitted. The diff distiller tracks content seen in prior turns using hash-based deduplication and replaces subsequent appearances with a reference to the first, along with only the lines that changed.
This is particularly effective in iterative development sessions where Claude reads a file, suggests changes, and then reads it again to verify the edit.
3. Smart Distillation (src/optimization/compressors/smart.ts)
JSON arrays with many similar objects (search results, file listings, API responses) often contain far more entries than the task requires. The smart distiller samples these: it keeps the first N entries, the last N entries, and replaces the middle with a count of omitted items.
Before:
[
{"file": "src/auth/login.ts", "line": 42, "match": "token"},
{"file": "src/auth/session.ts", "line": 18, "match": "token"},
... (47 more results)
{"file": "src/utils/crypto.ts", "line": 9, "match": "token"}
]After:
[
{"file": "src/auth/login.ts", "line": 42, "match": "token"},
{"file": "src/auth/session.ts", "line": 18, "match": "token"},
"[47 results omitted]",
{"file": "src/utils/crypto.ts", "line": 9, "match": "token"}
]The model sees the structure, the first and last entries, and the count. For most tasks, this is sufficient, and it uses a fraction of the tokens.
4. Search Distillation (src/optimization/compressors/search.ts)
Grep and code search results have a specific structure: they contain a query, a list of matches with line numbers and surrounding context, and often far more results than are relevant to the immediate task. The search distiller re-ranks matches by relevance to the current conversation context, truncates low-relevance matches, and preserves the highest-signal results.
5. Code Distillation (src/optimization/compressors/code.ts)
For large code blocks in tool results or assistant messages, the code distiller applies AST-aware reduction: stripping comments, collapsing function bodies that have already been discussed, and shortening type annotations where the shape is evident from context. This distiller is optional and requires tree-sitter; it activates automatically when the dependency is available.
Why Your Output Does Not Change
This is the trust question. If the proxy modifies the request, does it affect what Claude says? The answer is no, by design. The distillers remove redundant transmission, not semantic content. A build log that says "312 tests passed" in 200 lines becomes "312 tests passed" in 1 line. The model's understanding of the result is identical because the relevant signal is preserved.
The benchmark proves this empirically. scripts/benchmark.ts runs the same fixtures through the optimization pipeline and counts the token reduction. The fixtures are realistic multi-turn sessions from actual Claude Code usage patterns. The reduction is 20%. The optimization pipeline is deterministic: same input always produces the same output.
If you want to inspect what the distillers do to a specific piece of content, the source code is the ground truth.
Verify It Yourself
Three ways to confirm the claims in this post.
Run the benchmark:
npx tsx scripts/benchmark.tsThis runs the full optimization pipeline against the benchmark corpus and outputs the reduction percentage. It exits with code 0. The reductionPercent field should be 20.
Check your per-session stats:
thedistillery statsAfter running with the proxy active for a session, this command shows the raw versus optimized token counts for each session recorded in the local SQLite database. You can see the actual reduction in your own usage patterns, not just the benchmark corpus.
Read the source:
The distillers, the proxy server, and the benchmark fixtures are all in the GitHub repository. The optimization pipeline entry point is src/optimization/index.ts. The distillers are in src/optimization/compressors/. Each file is self-contained and under 200 lines.
How the Pipeline Stages Interact
The five distillers run in a deterministic order on each request, and the order matters. Log distillation runs first because compressing shell output before deduplication runs reduces the chance that two near-identical but verbose log blocks are treated as distinct. Diff distillation runs second because deduplicating earlier means subsequent stages see a smaller messages array. Smart and search distillation handle structured data after the bulk content has been compressed. Code distillation runs last because it depends on parser availability and operates on whatever code remains in the context.
Each stage is independent in the sense that disabling one does not break the others. If tree-sitter is unavailable, code distillation skips and the other four stages produce reduced but still meaningful output. The fail-safe behavior means the pipeline degrades rather than crashing when individual stages encounter unexpected content.
The deterministic ordering also means that the benchmark figure is reproducible. Running the same corpus through the same pipeline always produces the same output, which is the property that makes the 20% number a benchmark rather than an estimate.
Performance Characteristics
The proxy adds latency overhead per request, but the overhead is small relative to Anthropic's response times. Each distiller runs on the in-memory messages array using local CPU; no network or disk I/O is involved during the optimization pass. The total per-request optimization time on a typical Claude Code request is well under 50 ms, often closer to 10-20 ms on modern hardware.
Anthropic's API response times for Claude Sonnet typically range from 500 ms for short responses to several seconds for long generations. The proxy's optimization overhead is roughly 1-5% of Anthropic's response time, which makes it imperceptible in normal usage. The streaming response from Anthropic is forwarded byte-for-byte without buffering beyond what the underlying transport requires.
Memory usage is bounded by the size of a single request's messages array. The proxy does not retain request payloads after processing; each request is handled in isolation and the memory is reclaimed when the request completes. Long-running proxy instances do not accumulate state.
What Happens When Distillation Has Nothing to Reduce
For a request with no redundant content (a tightly scoped early-session request, for example), the pipeline produces near-zero reduction. The output messages array is essentially identical to the input. The 20% benchmark figure is averaged across a corpus of 8 sessions; individual sessions in the corpus range from roughly 12% to 35% reduction depending on content density.
This matters for understanding the per-session log. Seeing low reduction on a specific session is not a failure — it is an accurate report that the session contained little removable redundancy. Sessions that consistently report below 5% reduction across many runs may indicate workflow patterns (very short conversations, lean tool usage) that genuinely have little to optimize. Sessions reporting 30%+ have heavy redundancy that the pipeline successfully removed.
The distribution of reductions across a developer's workflow is informative. Heavy variance suggests mixed session types; consistent low reduction suggests already-lean usage; consistent high reduction suggests heavy agentic patterns where optimization has the largest absolute impact.
Failure Modes and Fallbacks
The pipeline is designed to fail safely. If a single distiller throws an unexpected error on a malformed input, the stage is skipped for that request and the remaining stages continue. The proxy never blocks a request due to optimization failure — the worst case is that one or more stages produce zero reduction for that specific request, which is identical in effect to bypass mode for that single request.
This design choice prioritizes availability over completeness. A request that would have reduced by 25% with all stages running but reduces by 18% because one stage hit a malformed input is a better outcome than a request that fails entirely. Claude Code never sees an error from the proxy; it only sees the same response Anthropic sends, possibly on a slightly larger payload than would have been optimal.
The fallback behavior is logged. The per-session log includes counts of stage failures, which surfaces unexpected input patterns. For developers contributing fixtures or filing bug reports, these counts are useful signals about which content types are challenging the pipeline.
Getting Started
npm install -g thedistillery
thedistillery startTwo commands. No configuration file. The proxy runs at localhost:3080 by default (override with DISTILLERY_PORT if needed).
The mechanism is transparent, the savings are measurable, and the workflow is unchanged.
Frequently Asked Questions
Q: Does the proxy work with Claude API clients other than Claude Code?
Yes. Any HTTP client that respects ANTHROPIC_BASE_URL (or that can be configured to point at a custom URL) routes through the proxy. The optimization pipeline operates on the messages array regardless of which client produced it. Tools that do not use the messages format (legacy completion endpoints, for example) pass through unchanged.
Q: Where is request data stored locally?
Per-session token counts are stored in a SQLite database at ~/.distillery/sessions.db. Raw request bodies are not stored by default — only the token counts and metadata. Logging behavior is configurable, but the default is metrics only, not full request capture.
Q: How does the pipeline handle streaming responses?
The proxy optimizes the request before forwarding, then streams the response from Anthropic back to Claude Code byte-for-byte. The response is not modified, buffered beyond minimal transport requirements, or processed by any pipeline stage. From Claude Code's perspective, streaming behavior is identical to direct Anthropic access.
Q: Can I add my own distiller to the pipeline?
The pipeline is deliberately closed: new distillers are added via pull request and shipped in a release, not loaded dynamically. This is a security-driven design choice. The proxy sits on the critical path of every API request and receives the full messages array; loading third-party code in-process would create an unbounded attack surface. Contributing a new distiller follows the same workflow as any open-source contribution.
Q: What happens if Anthropic changes the API request format?
The proxy parses the messages array using a permissive schema. New fields not yet handled by the distillers pass through unchanged. The pipeline degrades gracefully when it encounters unrecognized structure rather than failing the request. Updates that take advantage of new fields are shipped as part of normal proxy releases.
If the source does not answer a question, open an issue.
Try it on your own Claude Code sessions.
The Distillery applies these distillations automatically. Free until it saves you something.